Umfangreiche Datenbestände gibt es in Hülle und Fülle. Oft steht man vor dem Problem, nach einem bestimmten Datensatz im gegebenen Datenbestand zu suchen.
Wir spielen das im Folgenden hier einmal durch. Gegeben ist eine Datei mit Adressen von Personen.
Krause,Stefanie,Brandenburgische Str. 20,74343,Sachsenheim Brandt,Mandy,Scharnweberstrasse 84,68199,Mannheim Almenhof Möller,Jens,Schoenebergerstrasse 47,08313,Bernsbach Herzog,Marco,Scharnweberstrasse 90,61130,Nidderau Schmitz,Andreas,Meininger Strasse 84,66539,Neunkirchen Ludwigsthal Ebersbacher,Michelle,Alt-Moabit 10,06691,Zeitz Koertig,Christine,Hardenbergstraße 82,66887,Niederalben Schmidt,Vanessa,Paderborner Strasse 44,86359,Gersthofen Meister,Stephan,Fasanenstrasse 17,22605,Hamburg Othmarschen Schreiber,Barbara,Stresemannstr. 56,66592,St Wendel ...
Beachte, dass die Adressen hier Pseudo-Adressen sind. Die Personen gibt es in der Wirklichkeit nicht. Auch die Straßenangaben gibt es (in der Regel) in den betreffenden Orten nicht.
- Lade die Datei adressdaten_unsortiert.csv herunter und öffne sie mit einem Texteditor. Suche jetzt den Datensatz zur Person "Katja Herrmann aus Queidersbach". Eine vom Texteditor zur Verfügung gestellte Suchfunktion darfst du natürlich nicht benutzen.
- Lade auch die sortierte Datei adressdaten_sortiert.csv herunter und öffne sie mit einem Texteditor. Suche jetzt nochmal den Datensatz zur Person "Katja Herrmann aus Queidersbach". Warum fällt einem die Suche jetzt viel leichter?
- Begründe, warum man gerade bei großen Datenbeständen Operationen benötigt, die die Datensätze nach bestimmten Kriterien sortiert anordnen.
Umfangreiche Datenbestände werden heute in der Regel automatisiert verarbeit. Wir spielen auch diese Situation hier durch. Wir betrachten zunächst einen ungeordneten Datenbestand.
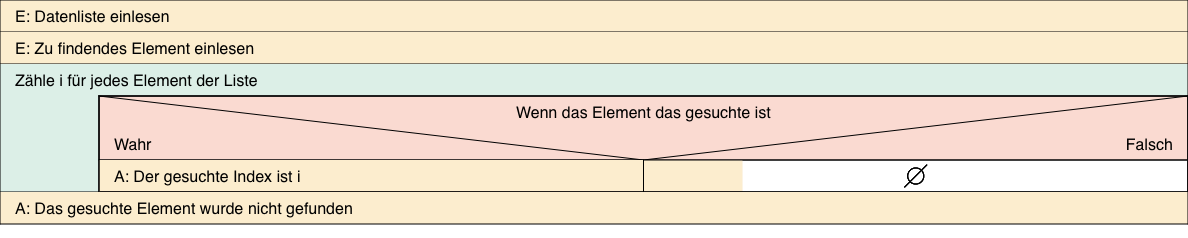
a) Entwickle einen Algorithmus als Struktogramm, mit dem man in der gezeigten, unsortierten Datenliste nach einer Person mit einem vorgegebenen Nachnamen suchen kann. Wenn der übergebene Name in der Datenliste vorkommt, dann soll der Index des zugehörigen Datensatzes zurückgegeben werden. Kommt der Name mehrfach vor, dann soll der Index des ersten passenden Datensatzes zurückgegeben werden. Kommt der Name in der Datenliste nicht vor, dann soll der Index -1 zurückgegeben werden.
b) Implementiere den Algorithmus in Processing und teste ihn. Verwende dazu die Vorlage unten.
Tipps:
- CSV-Dateien kann man in Processing mit Hilfe von Table.loadTable(dateiName) laden. Dazu muss die csv-Datei im Sketch-Ordner liegen.
- Mit table.getRowCount() kann man abfragen, wie viele Datensätze in einem Table enthalten sind.
- Mit table.getString(a, b) kann man den Inhalt der a. Zeile und b. Spalte abfragen.
- Um in Java zu ermitteln, ob zwei Strings identisch sind, benötigt man diese Methode:
public int equals(String anotherString)
int suchen(String name, Table liste) { // mit liste.getRowCount() kannst du die Anzahl der Datensätze auslesen // mit liste.getString(16, 3) kannst du die vierte Spalte des 17. Datensatzes auslesen // HIER KOMMT EUER ALGORITHMUS HIN! // Der Algorithmus soll den Index des gefundenen Datensatzes zurückgeben // oder -1, wenn kein passender Datensatz gefunden wurde. return -1; } void setup() { Table adressbuch = loadTable("adressdaten_unsortiert.csv"); println("Suche nach Nussbaum: " + suchen("Nussbaum", adressbuch)); println("Suche nach Frey: " + suchen("Frey", adressbuch)); println("Suche nach Test: " + suchen("Test", adressbuch)); }
- Betrachte verschiedene Szenarien:
- Funktioniert der Algorithmus aus Aufgabe 2 immer noch?
- Wann kann man jeweils die Suche abbrechen, wenn man die Daten des Datenbestandes der Reihe nach durchläuft?
- Passe den Pseudocode des Suchalgorithmus entsprechend an. Implementiere und teste ihn anschließend in Processing.
Tipp: Um in Java zu ermitteln, ob ein String größer oder kleiner als ein anderer String ist, benötigt man diese Methode: public int compareTo(String anotherString)
Die folgende Funktion benutzt ein Suchverfahren, das den Namen "binäre Suche" hat.
int suchen(String name, Table liste) { int links = 0; int rechts = liste.getRowCount() - 1; while (links <= rechts) { int mitte = (links + rechts) / 2; if (liste.getString(mitte, 0).compareTo(name) == 0) { return mitte; } else if (liste.getString(mitte, 0).compareTo(name) > 0) { rechts = mitte - 1; } else { links = mitte + 1; } } return -1; }
- Beschreibe den hier zu Grunde liegenden Algorithmus in eigenen Worten (als Struktogramm!). Verdeutliche ihn auch anhand von Beispielen.
- Teste die Funktion mit dem oben gegebenen sortierten Datenbestand.
int suchen(String name, Table liste) { int links = 0; int rechts = liste.getRowCount() - 1; while (links <= rechts) { int mitte = (links + rechts) / 2; if (liste.getString(mitte, 0).compareTo(name) == 0) { return mitte; } else if (liste.getString(mitte, 0).compareTo(name) > 0) { rechts = mitte - 1; } else { links = mitte + 1; } } return -1; } void setup() { Table adressbuch = loadTable("adressdaten_sortiert.csv"); // Hier kommen weitere Test hin! }
Vergleiche die beiden Suchalgorithmen.
- Welche Voraussetzungen benötigt der Algorithmus bzgl. der zu durchsuchenden Daten?
- Welcher Algorithmus ist einfacher / komplexer und warum?
- Welcher Algorithmus ist schneller?
unsortiert
int suchen(String name, Table liste) { int versuche = 0; for (int i = 0; i < liste.getRowCount(); i++) { versuche++; if (liste.getString(i, 0).equals(name)) { println("gv" + versuche); return i; } } println("nv" + versuche); return -1; } void setup() { Table adressbuch = loadTable("adressdaten_unsortiert.csv"); println("Suche nach Nussbaum: " + suchen("Nussbaum", adressbuch)); println("Suche nach Frey: " + suchen("Frey", adressbuch)); println("Suche nach Test: " + suchen("Test", adressbuch)); }
sortiert
int suchen(String name, Table liste) { int links = 0; int rechts = liste.getRowCount() - 1; int versuche = 0; while (links <= rechts) { versuche++; int mitte = (links + rechts) / 2; println("l" + links + "r" + rechts + "m" + mitte); if (liste.getString(mitte, 0).compareTo(name) == 0) { println("gv" + versuche); return mitte; } else if (liste.getString(mitte, 0).compareTo(name) > 0) { rechts = mitte - 1; } else { links = mitte + 1; } } println("nv" + versuche); return -1; } void setup() { Table adressbuch = loadTable("adressdaten_sortiert.csv"); println("Suche nach Nussbaum: " + suchen("Nussbaum", adressbuch)); println("Suche nach Frey: " + suchen("Frey", adressbuch)); println("Suche nach Test: " + suchen("Test", adressbuch)); }