Gutes Datenbankdesign zeichnet sich durch ein Minimum an Redundanz aus. Der unten dargestellte Datenbankausschnitt entspricht sehr schlechtem Datenbankdesign, da direkt auffällt, dass die Tabelle zahlreiche Redundanzen aufweist:
- Die Daten der beiden Kunden kommen jeweils drei mal vor.
- Hinzu kommt, dass die Spalten
KundeundAdressemehrwertige Daten enthalten, also Daten, die noch kleinschrittiger aufgeteilt werden könnten.

Redundante Daten können in Datenbanken schnell zu Anomalien führen können, die die automatische Datenverarbeitung sowie die Pflege der Datenbanksignifikant erschweren können und zur Inkonsistenz der Datenbank führen können.
Ein Beispiel für eine Einfügeanomalie wäre es, den folgenden Datensatz einzufügen. Die Rechnung mit der ID 1 hat nun auf einmal zwei Kunden. Ist nun der Kunde falsch eingegeben oder die Rechnungsnummer?

Ein Beispiel für eine Löschanomalie wäre es, die folgenden beiden Datensätze zu löschen. War es intendiert, die Rechnung zu löschen und der letzte Datensatz wurde übersehen? Oder wurden die beiden Rechnungspositionen korrekt gelöscht?

Ein Beispiel für eine Änderungsanomalie wäre es, die folgenden Datensätze zu verändern. Sollte die ganze Rechnung geändert werden? Oder wurden die beiden Rechnungspositionen vorher der falschen Rechnung zugeordnet?

Um Redundanz und damit verbundene Anomalien zu vermeiden, sind drei aufeinander aufbauende so genannte Normalformen entwickelt worden. Als Normalisierung bezeichnet man dementsprechend die Überführung einer Datenbanktabelle in eine Normalform höheren Grades.
Mit unserer bisherigen Erfahrung zum Thema Datenbanken könnten wir uns schnell eine Alternative überlegen. Anstatt die Daten wie oben in einer einzigen Relation ohne Schlüssel zu speichern, …
Rechnungen(RechnungsNr, Datum, KundenNr, Kunde, Adresse, RechnungsPosition, ArtikelNr, Artikel, Anzahl, Preis)
…, sollte man die Daten besser auf mehrere Relationen aufteilen und sinnvolle Schlüssel vergeben:
Kunden(KundenNr, Vorname, Nachname, Straße, PLZ, Ort)Artikel(ArtikelNr, Artikel, Preis)Rechnungen(RechnungsNr, Datum, #KundenNr)Rechnungsdaten(#RechnungsNr, RechnungsPosition, #ArtikelNr, Anzahl)
Warum das so ist und wie man das systematisch umsetzen kann, erklären im folgenden die drei Normalformen.
Eine Relation entspricht der 1. Normalform, wenn folgende Voraussetzungen erfüllt sind:
- Alle Daten liegen atomar vor. Ein Datensatz gilt als atomar, wenn jede Information einem eigenen Attribut zugeordnet ist.
- Alle Tabellenspalten beinhalten gleichartige Werte, in jedem Attribut können also nur Daten gleichen Typs gespeichert werden.
In der bereits bekannten Rechnungsrelation aus dem Einstiegsbeispiel wurden alle Daten hervorgehoben, die entweder nicht atomar sind oder die keine gleichwertigen Daten enthalten.

Um die Relation in die 1. Normalform zu überführen, sind folgende Schritte notwendig:
- Mehrwertigen Daten auf separate, atomare Attribute aufteilen. Hierzu müssen die Attribute
KundeundAdressein die spezifischeren AttributeVornameundNachnamebzw.Straße,PostleitzahlundOrtaufgeteilt werden3). - Jedes Attribut auf Gleichartigkeit überprüfen und ggf. Daten anpassen. In der Spalte
Preisfinden sich Angaben in Euro und in Cent. Hier muss sich für eine Darstellung entschieden werden.

Das Ergebnis ist eine Tabelle, die zwar der 1. Normalform entspricht, aufgrund doppelter Werte jedoch noch immer keine effiziente Datenverarbeitung erlaubt. Es empfiehlt sich daher, die Tabelle in die 2. Normalform zu überführen, um die Redundanzen zu beseitigen.
Eine Relation, die der 2. Normalform entsprechen soll, muss alle Voraussetzungen der 1. Normalform und zusätzlich folgende Bedingung erfüllen:
- Jedes Nichtschlüsselattribut muss vom kompletten Primärschlüssel abhängig sein.
In unserem Beispiel ist (noch) nicht ganz klar, was hier der Primärschlüssel sein könnte. Man könnte beispielsweise aus den Attributen Rechnungsnummer, Kundennummer und Rechnungsposition einen Primärschlüssel ableiten.

Somit wäre es möglich, mit den Werten $\left\{2, 2, 1\right\}$ den Datensatz, der für den Laptop-Kauf von Erika Musterfrau steht, eindeutig zu benennen:

Für solch eine eindeutige Identifizierung sind jedoch nicht sämtliche Angaben des ausgewählten Schlüssels erforderlich. Bereits eine Kombination aus Rechnungsnummer und Rechnungspositionsnummer würde dafür ausreichen, die einzelnen Datensätze eindeutig zu identifizieren.

Um die vorliegende Relation nun in die 2. Normalform zu überführen, gilt es jedoch nicht nur, einen Primärschlüssel und alle Nichtschlüsselattribute zu ermitteln, sondern auch deren Beziehung zueinander. Hierzu geht man folgendermaßen vor:
- Prüfen, ob alle Nichtschlüsselattribute vom gesamten Primärschlüssel abhängig sind. Eine solche Abhängigkeit ist nur dann gegeben, wenn alle Attribute des Primärschlüssels dafür notwendig sind, das Nichtschlüsselattribut eindeutig zu identifizieren5).
- Alle Nichtschlüsselattribute, die nur von einem Teil des Primärschlüssels abhängig sind, in separate Tabellen auslagern.
Wenn man sich die Beispieltabelle genau anschaut, sieht man, dass z.B. das Attribut Datum lediglich von der Rechnungsnummer, nicht aber von der Rechnungsposition abhängig ist. Das Gleiche gilt für die Kundendaten Vorname, Nachname, Straße, Postleitzahl und Ort.
Um die Datentabelle nun also in die 2. Normalform zu überführen, lagern wir alle Attribute, die lediglich von der Rechnungsnummer abhängig sind, in eine separate Tabelle mit dem Namen Rechnung aus. Die Tabelle mit den verbleibenden Daten nennen wir Rechnungsdaten.

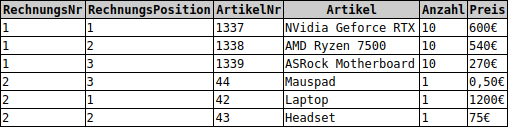
Die Rechnungsnummer findet sich nach der Normalisierung in beiden Tabellen und verknüpft diese miteinander. Während das Attribut in der Tabelle Rechnung als Primärschlüssel fungiert, kommt es in der Tabelle Rechnungsdaten als Fremdschlüssel zum Einsatz und ist zugleich Teil des zusammengesetzten Primärschlüssels der Tabelle.
Die Beispieldaten entsprechen nun der 2. Normalform. Gänzlich beseitigen ließen sich die Redundanzen dadurch aber noch nicht. Ziel einer Normalisierung ist daher in der Regel die 3. Normalform.
Soll eine Tabelle in die 3. Normalform überführt werden, müssen alle Voraussetzungen der 1. und 2. Normalform erfüllt sein und zusätzlich die folgende Bedingung:
- Kein Nichtschlüsselattribut darf nur transitiv von einem Schlüsselkandidaten abhängig sein. Eine transitive Abhängigkeit besteht dann, wenn ein Nichtschlüsselattribut von einem anderen Nichtschlüsselattribut und damit nur noch indirekt vom Primärschlüssel abhängig ist.
Unser Datenbankschema verletzt die Bedingungen der 3. Normalform gleich an mehreren Stellen. In der Tabelle Rechnung sind die Attribute Vorname, Nachname, Straße, Postleitzahl und Ort nicht nur vom Primärschlüssel (der Rechnungsnummer), sondern auch von der Kundennummer abhängig. In der Tabelle Rechnungsdaten sind die Attribute Artikel und Preis nicht nur vom Primärschlüssel (Rechnungsnummer und Rechnungsposition) abhängig, sondern auch von der Artikelnummer.

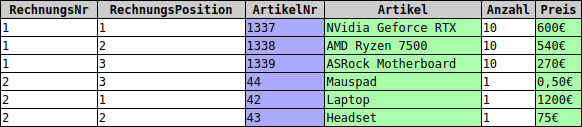
Um alle Abhängigkeiten zwischen Nichtschlüsselattributen zu beseitigen, lagern wir die entsprechenden Attribute in separate Tabellen aus, die durch Fremdschlüssel miteinander verknüpft werden. Es ergeben sich somit die vier normalisierten Tabellen, die uns der Form her bereits aus der Northwind-Datenbank bekannt sind:
Kunden(KundenNr, Vorname, Nachname, Straße, PLZ, Ort)Artikel(ArtikelNr, Artikel, Preis)Rechnungen(RechnungsNr, Datum, #KundenNr)Rechnungsdaten(#RechnungsNr, RechnungsPosition, #ArtikelNr, Anzahl)


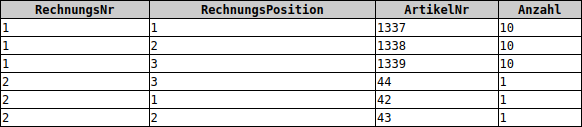
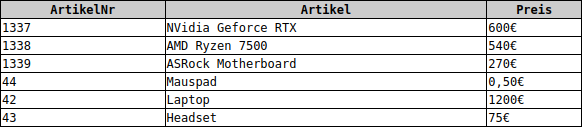
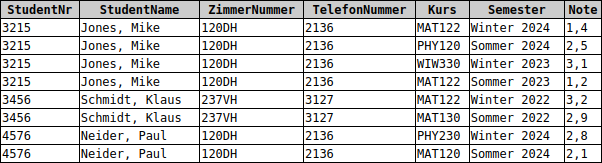
Bringe die vorliegenden Datenbanken jeweils in die 3. Normalform:
a) Studentenwohnheim mit Kursbelegungen und Noten
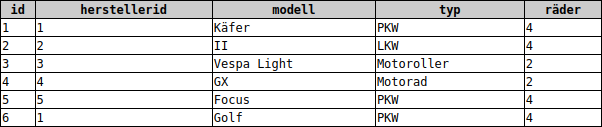
b) Automodelle-Hersteller-Datenbank

a)
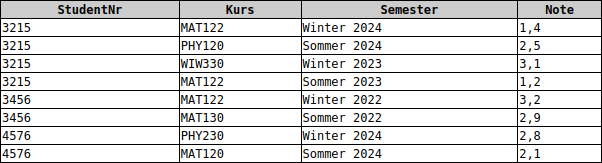
Studenten(StudentNr, Vorname, Nachname, ZimmerNummer, TelefonNummer)

Kursbelegungen(#StudentNr, Kurs, Semester, Note)
b)
Autohersteller(HerstellerID, Hersteller, Straße, PLZ, Ort, Land)

Automodell(ModellID, #HerstellerID, Modell, Typ, Räder)
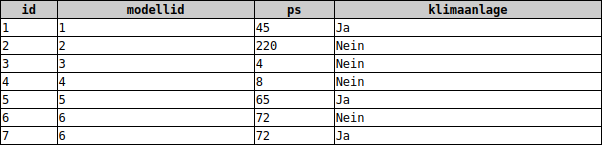
Autoausstattung(AutoID, #ModellID, PS, Klimaanlage)
In diesem Beispiel mag es wenig effizient erscheinen, eine Tabelle mit nur sechs Datensätzen in vier Tabellen aufzuspalten. Tatsächlich fallen die Redundanzen bei den Daten von lediglich zwei Kunden kaum ins Gewicht. Was ist nun aber, wenn man die Daten mehrerer Hunderttausend Kunden samt deren Bestellungen konsistent und widerspruchsfrei in einer Datenbank speichern und verarbeiten will? Dies gelingt in der Regel nur mit einem Datenbankschema, das der 3. Normalform entspricht. Unsere bereits bekannten Beispieldatenbanken liegen alle (mehr oder minder) in der 3. Normalform vor.
Auch wenn die Normalisierung von Datenbanken mit einem höheren Aufwand verbunden ist die 3. Normalform allgemein als Standard für relationale Datenbankschemata, von dem nur in Ausnahmefällen abgewichen wird. Andererseits geht die Normalisierung von Datenbanken immer mit der Auslagerung von Attributen in separate Tabellen einher. Dies erfordert möglicherweise die Integration von Fremdschlüsseln. Der zentrale Nachteil jedoch ist, dass logisch zusammengehörige Daten in einer normalisierten Datenbank nicht mehr zusammen gespeichert werden, sondern in separaten Tabellen.
Möchte man Daten, die auf verschiedene Tabellen aufgeteilt wurden, zusammenführen, ist zunächst ein Join erforderlich. Per Datenbankabfragen über Joins lassen sich komplexe Informationen herausfiltern. In der Umsetzung sind Joins jedoch aufwendiger als einfache Abfragen. Hinzu kommt ein deutlich größerer Zeitaufwand, wenn Joins über eine Vielzahl von Datenbanktabellen erfolgen.