Mit den Aggregatfunktionen werden statistische Auswertungen numerischer Daten in einer Datenbank vorgenommen. Jede Aggregatfunktion wird auf ein Attribut einer Tabelle angewendet und liefert als Ergebnis einen Zahlenwert zurück. Mit deren Hilfe kann man z.B. die Anzahl an Datensätzen ermitteln oder die Summe, das Maximum/Minimum bzw. den Durchschnitt der Werte eines Attributes berechnen.
Die Anzahl aller Datensätze einer Tabelle zählt man mit COUNT(*).
SELECT COUNT(*) AS AnzahlBestellungen FROM Orders;
COUNT(Spalte) zählt die Anzahl der von NULL verschiedenen Werte einer Spalte in der Ergebnistabelle.
SELECT COUNT(ShippedDate) AS Versendete FROM Orders;
SELECT COUNT(*) - COUNT(ShippedDate) AS NichtVersendete FROM Orders;
Will man nur die verschiedenen Werte einer Spalte zählen, so benutzt man COUNT(DISTINCT Spalte).
SELECT COUNT(DISTINCT ShipCountry) AS AnzahlLänder FROM Orders;
Der SUM(Spalte)-Befehl zählt die aus der Abfrage resultierenden Zahlenwerte der Spalte zusammen, auf die er angewendet wird.
SELECT SUM(unitsInStock) AS AnzahlProdukte FROM Products;
SELECT SUM(UnitsInStock) AS LagerbestandMorgens, SUM(UnitsOnOrder) AS BestellteProdukte, SUM(UnitsInStock) - SUM(UnitsOnOrder) AS LagerbestandAbends FROM Products;
Benutzt man diese Befehle, so erhält man die größte/kleinste Zahl, also das Maximum/Minimum der Spalte.
SELECT MIN(unitPrice) AS KleinsterPreis FROM Products;
SELECT MAX(unitPrice) AS GrößterPreis FROM Products;
AVG(Spalte) ermittelt den Mittelwert (Durchschnitt) aller Zahlenwerte einer Spalte.
SELECT AVG(unitPrice) AS DurchschnittsPreis FROM Products;
Dabei werden alle Einträge addiert und dann durch die Anzahl der Einträge geteilt. Das könnten wir aber auch mit den bisher bereits bekannten Aggregatsfunktionen ermitteln:
SELECT SUM(unitPrice) / COUNT(unitPrice) AS DurchschnittsPreis FROM Products;
Ohne Gruppierungen (die kommen gleich noch) kann man Aggregatsfunktionen nicht sinnvoll mit der Auswahl anderer Spalten mischen. In den meisten Datenbanksystemen kommt es dann zu einem Fehler. SQLite lässt solche Abfragen zu, allerdings ergeben die Ergebnisse dann nur wenig sinn.
Möchte man zum Beispiel wissen, welcher Lieferant die meisten Produkte im Lager hat, könnte man diese Abfrage erstellen. Diese liefert allerdings (offensichtlich) nicht das gewünschte Ergebnis.
SELECT SupplierID, SUM(UnitsInStock) FROM Products;

3119 Produkte waren insgesamt im Lager, schaut man sich die gesamte Tabelle an, fällt (durch manuelles Nachzählen) auf, dass der Lieferant mit der SupplierID 1 nur 69 Produkte im Lager hat.
Wer mehr wissen möchte, kann diesen Artikel lesen.
Nutze die CIA-Datenbank:
- Wie viele Länder enthält die cia-Datenbank?
- Ermittle die Weltbevölkerung.
- Gib das Durchschnitts-Bruttoinlandsprodukt an.
- Wie groß sind Bevölkerung und Bruttoinlandsprodukt für ganz Europa?
- Ermittle die Flächen des kleinsten und größten Landes.
- Wie viele Regionen gibt es?
a)
SELECT COUNT(*) FROM cia
b)
SELECT SUM(einwohner) FROM cia
c)
SELECT avg(bip) FROM cia
d)
SELECT SUM(einwohner), SUM(bip) FROM cia WHERE region = "Europa"
e)
SELECT MIN(fläche), MAX(fläche) FROM cia
f)
SELECT COUNT(DISTINCT region) FROM cia
Mit der GROUP BY-Klausel kann man Datensätze in Gruppen einteilen. Dabei wird jeder Datensatz genau einer Gruppe zugeordnet. Hat man die Datensätze mittels GROUP BY in Gruppen eingeteilt, so kann man nur noch Angaben über die Gruppen machen, nicht mehr über einzelne Datensätze.
Wir können die Datensätze der cia-Datenbank nach den Regionen gruppieren und dann die Regionen ausgeben.
SELECT Region FROM cia GROUP BY Region
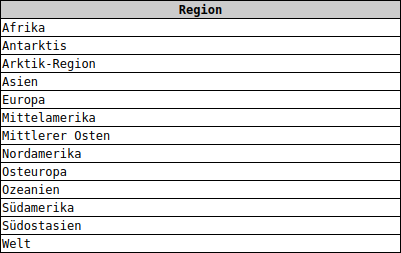
Das obige Beispiel ist untypisch, weil man das Ergebnis einfacher auch so erhält:
SELECT DISTINCT Region FROM cia
Der Mehrwert der GROUP BY-Klausel ergibt sich daraus, dass man mit den Aggregatfunktionen statistische Auswertungen der Gruppen vornehmen kann: Wir wollen die gesamte Einwohnerzahl der einzelnen Regionen und deren durchschnittliches Bruttosozialprodukt ausgeben:
SELECT Region, SUM(Einwohner), AVG(BIP) FROM cia GROUP BY Region
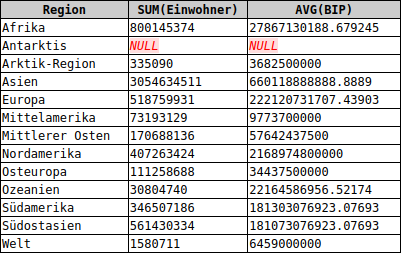
Der typische Fehler im Zusammenhang mit der Gruppierung besteht darin, dass nach der Gruppenbildung noch versucht wird, Informationen von einzelnen Datensätzen auszugeben. Zum Beispiel:
SELECT Region, Name, SUM(Einwohner), AVG(BIP) FROM cia GROUP BY Region
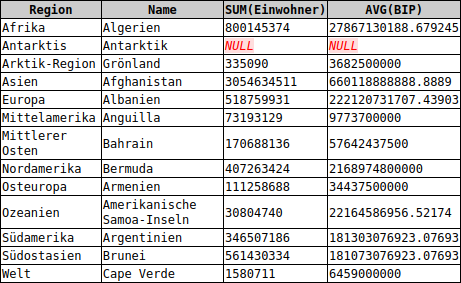
Man kann zwar für jede Gruppe die Region und die Summe der Einwohner angeben, aber nicht den Namen, denn der ist für jedes Land einer Region anders.
Die meisten Datenbanksysteme weisen diese SELECT-Anweisung mit einer Fehlermeldung zurück. Sinngemäß heißt es meist, dass das Attribut Name nicht Bestandteil der GROUP BY-Klausel ist. SQLite bildet hier eine Ausnahme, akzeptiert die SELECT-Anweisung und liefert das obige Ergebnis.
Interpretation
Dass das gelieferte Ergebnis tatsächlich fragwürdig ist, zeigt sich gleich beim ersten Datensatz. Für die Region Afrika wird als Name Algerien angegeben. Hier wird also zur Gruppe Afrika das Einzeldatum Name ausgegeben.
Wir halten also fest, dass bei einer SELECT-Anweisung mit GROUP BY in der SELECT-Klausel nur die Gruppierungsattribute und die Aggregatfunktionen vorkommen dürfen.
Wenn man nicht an allen Gruppen interessiert ist, so kann man mit der HAVING-Klausel die in Frage kommenden Gruppen auswählen. Bildlich bedeutet das, dass man einige der entstandenen Gruppen von der weiteren Betrachtung ausschließt.
Aber nach welchen Kriterien kann man Gruppen auswählen? Das geht nur mit einer Gruppeneigenschaft, also entweder danach wie die Gruppen gebildet wurden oder mit einer Aggregatsfunktion, die eine Gruppeneigenschaft bestimmt. Deshalb wird in einer HAVING-Klausel in aller Regel eine Aggregatfunktion benutzt, während in einer WHERE-Klausel keine Aggregatfunktion möglich ist.
Es sollen die Regionen angezeigt werden, die mehr als 100 Millionen Einwohner haben.
SELECT Region, SUM(Einwohner) FROM cia GROUP BY Region HAVING SUM(Einwohner) > 1E08
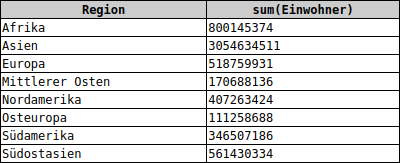
Auch eine SELECT-Anweisung mit GROUP BY-Klausel kann eine WHERE-Bedingung enthalten. Die WHERE-Bedingung wählt aus der gesamten Datenmenge die Datensätze aus, die anschließend gruppiert werden.
Es sollen die Einwohnerzahlen der Regionen angezeigt werden, wobei nur Länder mit mehr als 100 Millionen Einwohner berücksichtigt werden sollen.
SELECT Region, SUM(Einwohner) FROM cia WHERE Einwohner > 1E08 GROUP BY Region
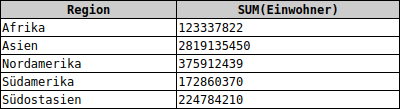
Um das Zustandskommen der Werte besser verstehen zu können, wandeln wir die SELECT-Anweisung so ab, dass wir die Einwohnerzahlen der beteiligten Länder ausgeben. Dazu ergänzen wir in der GROUP BY-Klausel und in der SELECT-Klausel das Attribut Name. Die Gruppierung wird dann über die Kombination der Attribute Region und Name durchgeführt.
SELECT Region, Name, SUM(Einwohner) FROM cia WHERE Einwohner > 1E08 GROUP BY Region, Name
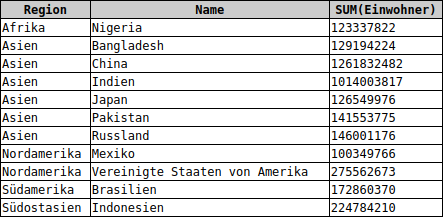
In der Region Nordamerika gibt es die zwei Länder Mexiko und die Vereinigte Staaten von Amerika mit mehr als 100 Millionen Einwohner. Die Summe ihrer Einwohnerzahlen wurde in der vorherigen Abfrage ermittelt.
Kommen in einer Abfrage WHERE, GROUP BY und HAVING vor, so wird in dieser Reihenfolge das Ergebnis bestimmt.
- Zuerst werden die zu betrachtenden Datensätze mittels
WHEREselektiert. - Dann werden diese mit
GROUP BYgruppiert. - Zum Schluss werden sie mit
HAVINGdie gewünschten Gruppen ausgewählt.
Wir gruppieren wieder die Länder mit mehr als 100 Millionen Einwohner, nehmen davon aber nur die Regionen mit mehr als 250 Millionen Einwohnern.
SELECT Region, SUM(Einwohner) FROM cia WHERE Einwohner > 1E08 GROUP BY Region HAVING SUM(Einwohner) > 250000000

Nutze die CIA-Datenbank:
- Zeige von jeder Region den Namen und die Anzahl der Länder an.
- Zeige für alle Regionen den Namen und die Anzahl der Länder mit mehr als 10 Millionen Einwohnern an.
- Welche Regionen haben eine Gesamtbevölkerung von mindestens 100 Millionen?
- Stelle die Regionen der Erde mit Einwohnerzahl und Gesamtfläche dar, geordnet nach der Einwohnerzahl.
- Wie Aufgabe 4 aber nur die Regionen von Amerika.
Jetzt geht es mit der WMTitel-Datenbank weiter.
- Ermittle die von jedem Weltmeister erreichte Gesamtzahl von WM-Punkten und stelle das Ergebnis nach WM-Punkten geordnet dar.
- Welche Gesamtpunktzahlen der Konstrukteursweltmeisterschaft haben die Teams in den neunziger Jahren erreicht?
- Wie vorherige Aufgabe, allerdings sollen nur Teams mit mindestens 100 Punkten ausgegeben werden.
- Ermittle für die Jahre, in denen Michael Schumacher gefahren ist, die durchschnittliche Zahl der erreichten Team-Punkte des Konstrukteursweltmeisters und stelle die Liste geordnet dar.
- Ermittle ab 1995 in geordneter Reihenfolge die Gesamtzahl der Team-Punkte für Teams mit mindestens 200 Punkten.
1a)
SELECT region, COUNT(*) FROM cia GROUP BY region
1b)
SELECT region, COUNT(*) FROM cia WHERE Einwohner > 10E6 GROUP BY region
1c)
SELECT region, SUM(einwohner) FROM cia GROUP BY region HAVING SUM(einwohner) > 100E6
1d)
SELECT region, SUM(einwohner), SUM(Fläche) FROM cia GROUP BY region ORDER BY SUM(einwohner) DESC
1e)
SELECT region, SUM(einwohner), SUM(Fläche) FROM cia WHERE region LIKE '%amerika%' GROUP BY region ORDER BY SUM(einwohner) DESC
2a)
SELECT fahrerweltmeister, SUM(wm_punkte) FROM wmtitel GROUP BY fahrerweltmeister ORDER BY SUM(wm_punkte) DESC
2b)
SELECT konstrukteurswm, SUM(team_punkte) FROM wmtitel WHERE saison BETWEEN 1990 AND 1999 GROUP BY konstrukteurswm
2c)
SELECT konstrukteurswm, SUM(team_punkte) FROM wmtitel WHERE saison BETWEEN 1990 AND 1999 GROUP BY konstrukteurswm HAVING SUM(team_punkte) > 100
2d)
SELECT KonstrukteursWM, AVG(Team_Punkte) FROM WMTitel WHERE Fahrerweltmeister = "Michael Schumacher" GROUP BY KonstrukteursWM ORDER BY AVG(Team_Punkte) DESC
2e)
SELECT KonstrukteursWM, SUM(Team_Punkte) FROM WMTitel WHERE Saison >= 1995 GROUP BY KonstrukteursWM HAVING SUM(Team_Punkte) >= 200 ORDER BY SUM(Team_Punkte) DESC
Die DQL-Anweisungen haben alle folgende grammatische Struktur, wobei optionale Anteile in [Klammern] gesetzt sind und der senkrechte Strich Alternativen beschreibt:
SELECT [DISTINCT] Selectausdruck, ... FROM Tabellen, ... [WHERE Bedingung [AND | OR] ...] [GROUP BY spalten_name [ASC | DESC], ...] [HAVING Bedingung [AND | OR] ...] [ORDER BY spalten_name [ASC | DESC], ...] [LIMIT [offset,] zeilen]
Datenbanksysteme werteen diese Klauseln in der Reihenfolge FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY, LIMIT aus. Dabei funktionieren die Klauseln im Sinne einer Pipeline, das heißt die Ausgabe einer Klausel ist die Eingabe für die nächste. In funktionaler Notation wird die Reihenfolge der Auswertung wie folgt dargestellt:
LIMIT(ORDER BY(SELECT(HAVING(GROUP BY(WHERE(FROM…))))))