Wie ihr in der letzten Stunde gesehen habt, bestehen Datenbanken (in der Regel) aus mehr als nur einer Tabelle. Hierbei gibt es natürlich auch Abhängigkeiten der Tabellen untereinander.
So gibt es z.B. folgende Tabellen in der chinook-Mediendatenbank:
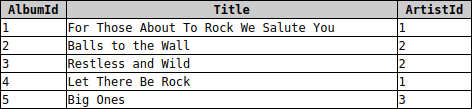

Wie unschwer zu erkennen ist, gibt es eine Abhängigkeit zwischen den beiden Tabellen. So hat jedes Album über das Attribut ArtistID die ID eines bestimmten Interpreten gespeichert. Somit kann man also sagen, dass das Album Big Ones vom Interpreten Aerosmith eingespielt wurde.
Um die Struktur von Datenbanken besser darstellen zu können, nutzen wir so genannte ER-Diagramme. In diesen werden Entitäten (Tabellen) mit ihren Attributen (Spalten) und den Beziehungen zwischen den Entitäten dargestellt. Hierbei steht ERD für "Entity Relationship Diagram". Die Daten, die in einer Tabelle gespeichert werden, werden hier ignoriert, es geht nur um die Struktur.
Das Beispiel von oben (Albums & Artists) sieht als ERD so aus:

Die Entitäten werden als Rechtecke dargestellt, die Attribute als Ellipsen.
Die Beziehungen sind etwas komplexer. Diese werden durch eine Raute dargestellt und enthalten so genannte Kardinalitäten (das sind das N neben Album und die 1 neben Artist). Was das genau bedeutet, kommt später noch.
Außerdem werden manche Attribute unterstrichen dargestellt (AlbumID und ArtistID), das sind so genannte Primärschlüssel (genaue Erklärung folgt noch). Ebenso werden manche Attribute weg gelassen (in Album fehlt die ArtistID), das wäre ein Fremdschlüssel (auch hier: Erklärung folgt noch).
Eine andere Darstellung für die Struktur einer Datenbank kennt ihr bereits. Das so genannte Relationenmodell:
albums(AlbumId, Title, #ArtistId)artists(ArtistId, Name)
Hier werden die Attribute einer Entität in Klammern hinter dem Entitätsnamen aufgelistet. Primärschlüssel werden unterstrichen, Fremdschlüssel entweder mit einem # oder einem ↑ gekennzeichnet.
Doch was sind eigentlich diese Schlüssel, von denen die ganze Zeit die Rede ist? Schauen wir uns noch einmal die beiden Tabellen aus dem Einstiegsbeispiel genauer an:
So wie es aussieht, hat jedes Album seine eigene AlbumID, diese wird nicht doppelt vergeben. Das könnt ihr auch in der vollständigen Datenbank gerne nocheinmal überprüfen. Primärschlüssel sind also Attribute, die jeden Datensatz eindeutig kennzeichnen. Manchmal werden auch mehrer Attribute zu einem zusammengesetzten Primärschlüssel zusammengefasst.
Möchte man nun die Beziehung "Ein Album wird von einem Artist produziert" in einer Datenbank modellieren, so kann man einfach den Primärschlüssel der referenzierten Entität als Fremdschlüssel in einer anderen Entität speichern. In diesem Beispiel ist ArtistID der Primärschlüssel von der Entität Artist und gleichzeitig der Fremdschlüssel in der Entiät Album.
In diesem Beispiel gibt es also insgesamt drei Schlüsselattribute:
- Der Primärschlüssel
AlbumIDin der TabelleAlbum - Der Primärschlüssel
ArtistIDin der TabelleArtist - Der Fremdschlüssel
ArtistIDin der TabelleAlbum
Lest die Abschnitte "Kardinalität (Datenbankmodellierung)", "Ausführliche Definition" und "Einteilung" (noch nicht weiter lesen!!) des Artikels zu Kardinalitäten auf Wikipedia. Beantwortet die folgenden Fragen im Gruppendokument:
a) Was ist eine Kardinalität?
b) Welche Kardinalitäten gibt es?
Im Abschnitt Beispiele findet ihr Beispiele zu den einzelnen Kardinalitäten.
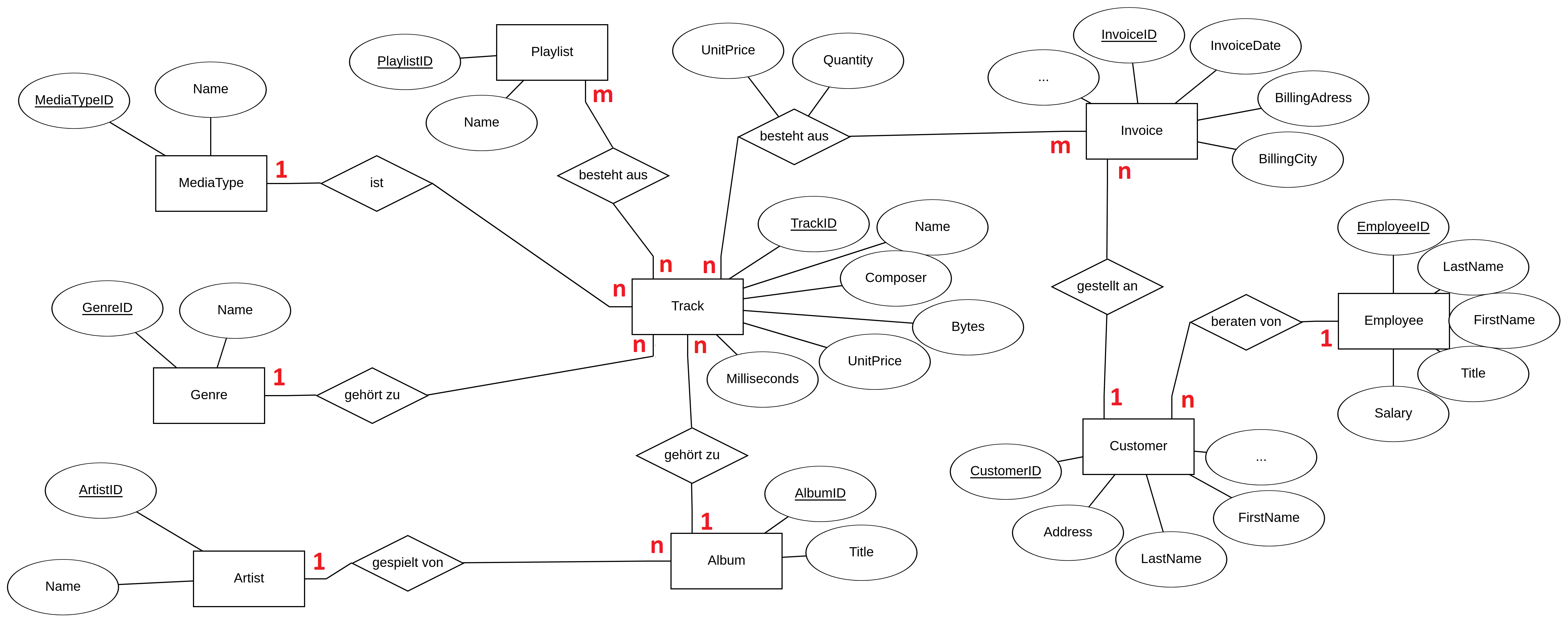
c) Schreibt im ER-Diagramm unten die Kardinalitäten an die Beziehungen.
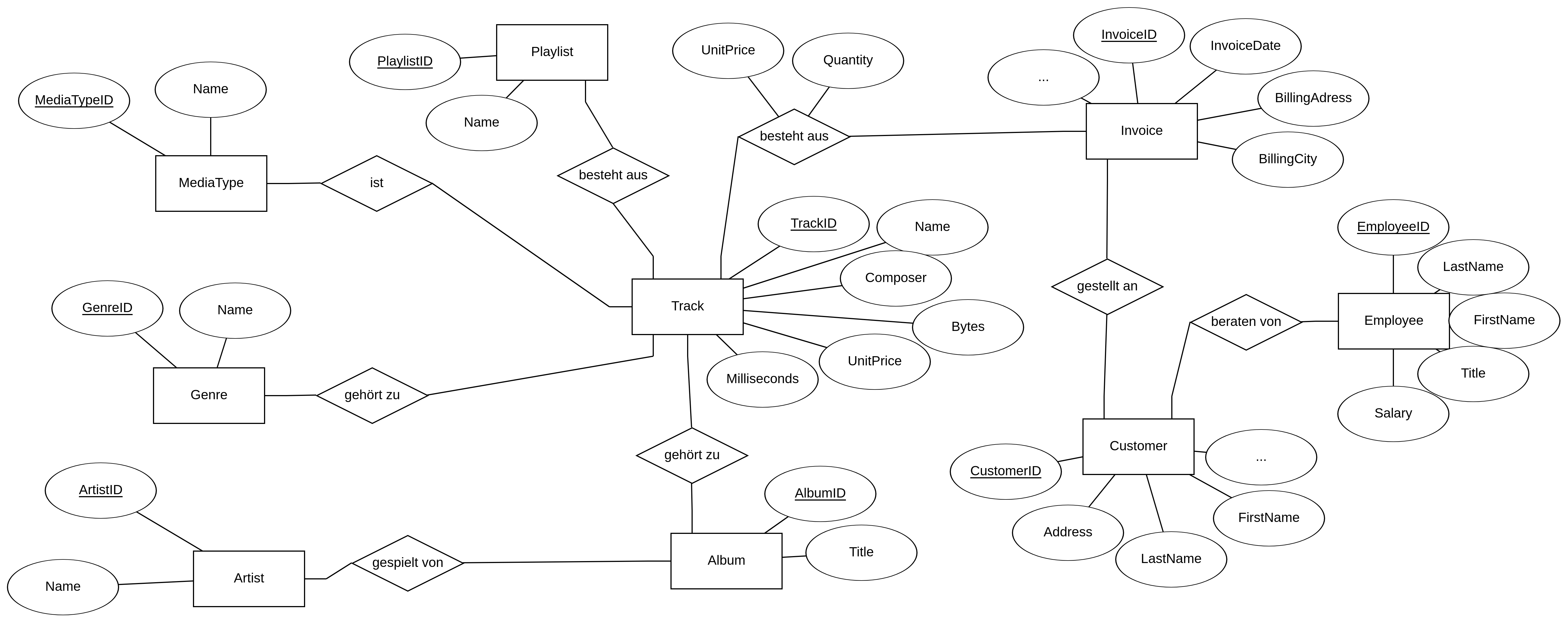
Seht euch an, wie die Tabellen der chinook-Mediendatenbank aufgebaut sind. Vergleicht diese mit dem ER-Modell. Was fällt euch auf? Vergleicht insbesondere die m:n-Beziehung zwischen Playlist und Track mit der 1:n-Beziehung zwischen Album und Artist.
d) Notiert eure Beobachtungen im Gruppendokument.
Die verscheidenen Beziehungstypen können in SQL auf unterschiedliche Weise umgesetzt werden. Lest dazu den Abschnitt Umsetzung des ER-Modells in Datenbanktabellen im relationalen Datenmodell .
e) Notiert euch wichtige Informationen im Gruppendokument.
f) Erstellt ein vollständiges ER-Diagramm zur Nordwind-Datenbank.
- Nutzt die Software ERDPlus!
- Ihr müsst in "großen" Tabellen nicht alle Attribute übernehmen, nur die wichtigsten
- Kopiert euer fertiges ERD in euer Gruppendokument!
In den Folien der Informatikzentrale zur Relationenschreibweise und zum Relationenmodell findet ihr einige Übungsaufgaben. Bearbeitet diese und speichert eure Antworten im Gruppendokument.
Wir betrachten erneut das Beispiel von oben aus der Chinook-Mediendatenbank.
Schön wäre es, mit einer einzigen Abfrage eine Liste aller Alben mit den jeweiligen Interpreten bekommen zu können:
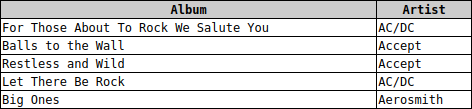
Um das zu bewerkstelligen, kann man eine Abfrage über beide Tabellen erstellen. Dies nenn man einen sogenannen Join, da mehrere Tabellen zu einer einzigen zusammengefügt werden. Betrachtet man nun aber das Ergebnis, fällt auf, dass die Ergebnistabelle aus den Spalten der Artists-Tabelle und den Spalten der Albums-Tabelle zusammen besteht. Jedoch wird man schnell merken, dass da etwas nicht stimmt:
SELECT * FROM albums, artists
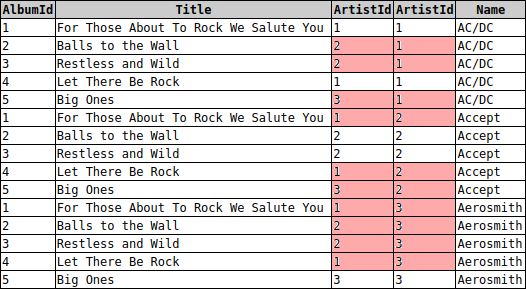
Ein Join verbindet einfach ohne jede Logik jeden Datensatz der ersten Tabelle mit allen Datensätzen der zweiten Tabelle. Somit werden auch viele "ungewünschte" Ergebnisse erzeugt (rot markiert).
Um nun nur die gewünschten Ergebnisse zu bekommen, müssen wir nun noch diejenigen Datensätze herausfiltern, in denen die ArtistID in beiden Tabellen übereinstimmt. Hierbei taucht ein kleines Problem auf. Den Spaltennamen ArtistID gibt es in beiden Tabellen, einmal als Primärschlüssel der Artists-Tabelle und einmal als Fremdschlüssel der Albums-Tabelle. Deshalb muss man genauer spezifizieren, welche Spalte man meint: Albums.ArtistID meint dann eben den Fremdschlüssel ArtistID aus der Tabelle Albums.
SELECT * FROM albums, artists WHERE artists.artistid = albums.artistid

Dies liefert endlich das gewünschte Ergebnis. Nun kann man noch die entsprechenden Spalten einschränken, und schon ist die Tabelle so, wie wir sie haben wollten:
SELECT albums.title AS Album, artists.name AS Artist FROM albums, artists WHERE artists.artistid = albums.artistid
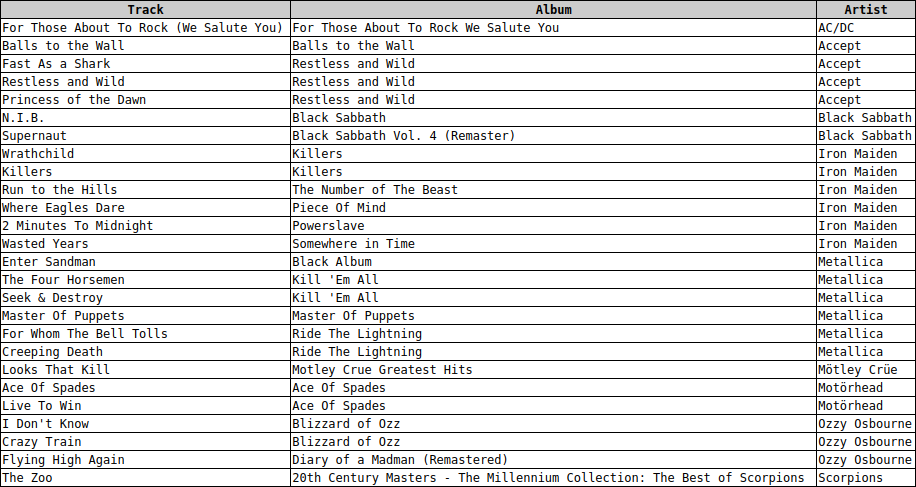
Natürlich kann man auch mehr als nur zwei Tabellen mit einem Join miteinander verbinden. Möchte man z.B. wissen, welche Tracks (mit Album und Artist) auf der Playlist "Heavy Metal Classic" gespeichert sind, muss man einen 5-fach-Join verwenden:
SELECT tracks.name AS Track, albums.title AS Album, artists.name AS Artist FROM playlists, playlist_track, tracks, albums, artists WHERE playlist_track.playlistid = playlists.playlistid AND tracks.trackid = playlist_track.trackid AND tracks.albumid = albums.albumid AND artists.artistid = albums.artistid AND playlists.name = 'Heavy Metal Classic'
Öffne die Northwind-Datenbank. Erstelle für jede Abfrage unten eine SQL-Anweisung mit Joins. Notiere die Ergebnisse im Gruppendokument:
- Zu welcher Kategorie gehören die 'Teatime Chocolate Biscuits'?
- Erstelle eine Abfrage mit den Attributen ProductID, ProductName und CompanyName des Lieferanten (Supplier)
- Über welche Versandfirma wurde die Bestellung mit der OrderID 10266 ausgeliefert?
- Welcher Mitarbeiter ist für die Bestellung mit der OrderID 10266 zuständig?
- Erstelle eine Abfrage mit ProductID, ProductName, CompanyName des Lieferanten (Supplier) und CategoryName.
- Gib die Artikelliste für die Bestellung 11031 mit Einzelpreis und Gesamtpreis aus, wobei sich der Gesamtpreis aus der Anzahl und dem Einzelpreis ergibt.
- Für welche Kunden hat der Mitarbeiter Buchanan schon Bestellungen abgewickelt?
- Die Produkte der Bestellung der Rattlesnake Canyon Grocery vom 1998-05-06, die nicht mehr in ausreichender Anzahl auf Lager sind
- Welche Artikel hat der Kunde 'Richter Supermarkt' schon bestellt?
- Welche Kunden haben schon Artikel der Firma 'Escargots Nouveaux' gekauft?
1)
SELECT categories.categoryname FROM products, categories WHERE products.categoryid = categories.categoryid AND products.productname = 'Teatime Chocolate Biscuits'
2)
SELECT productid, productname, companyname FROM products, suppliers WHERE products.supplierid = suppliers.supplierid
3)
SELECT shippers.companyname FROM orders, shippers WHERE orders.shipvia = shippers.shipperid AND orderid = 10266
4)
SELECT lastname, firstname FROM orders, employees WHERE orders.employeeid = employees.employeeid AND orders.orderid = 10266
5)
SELECT productid, productname, companyname, categoryname FROM products, suppliers, categories WHERE products.categoryid = categories.categoryid AND products.supplierid = suppliers.supplierid
6)
SELECT products.productid, productname, products.unitprice, quantity, products.unitprice * quantity AS Gesamtpreis FROM products, orderdetails WHERE products.productid = orderdetails.productid AND orderid = 11031
7)
SELECT DISTINCT(companyname) FROM customers, employees, orders WHERE customers.customerid = orders.customerid AND employees.employeeid = orders.employeeid AND lastname = 'Buchanan'
8)
SELECT products.productid, productname, products.unitsinstock, orderdetails.quantity FROM products, customers, orders, orderdetails WHERE products.productid = orderdetails.productid AND orders.orderid = orderdetails.orderid AND customers.customerid = orders.customerid AND customers.companyname = 'Rattlesnake Canyon Grocery' AND orders.orderdate LIKE '1998-05-06%' AND products.unitsinstock < orderdetails.quantity
9)
SELECT products.* FROM customers, orders, orderdetails, products WHERE customers.customerid = orders.customerid AND orders.orderid = orderdetails.orderid AND products.productid = orderdetails.productid AND customers.companyname = 'Richter Supermarkt'
10)
SELECT DISTINCT(customers.companyname) FROM customers, orders, orderdetails, products, suppliers WHERE customers.customerid = orders.customerid AND orders.orderid = orderdetails.orderid AND orderdetails.productid = products.productid AND suppliers.supplierid = products.supplierid AND suppliers.companyname = 'Escargots Nouveaux'